Trending News
16 October, 2024
10.9°C New York

TikTok’s latest offering is capitalizing on the app’s ability to serve as a discovery engine for other media — something its users already take advantage of by sharing short clips of movies and TV shows. Today, the company is partnering with studios like Warner Bros. to launch a feature that lets users discover movies and TV shows through the short-form video app.
The new feature, called “Spotlight,” appears on videos related to a film or series, and directs users to a dedicated landing page where they can learn additional information about the title, such as the synopsis, cast, as well as short video content from creators. From the landing page, users can watch the title on streaming services (such as Max), rent on-demand, or buy movie tickets to see it in theaters.
Videos that qualify for Spotlight links must have a certain number of views and creators with a decent following. Creators participating in a Spotlight campaign can earn various incentives, such as exclusive frames for their profile photo, filters, merchandise, movie tickets, and even access to red-carpet events.

Warner Bros., with its vast IP library of popular titles, is using Spotlight to promote the second season of “House of the Dragon.” It’s currently rewarding creators for posting videos about the show — whether that be a review, funny skit, makeup tutorial, and so on – with a limited profile frame for their preferred House: Team Green or Team Black. Creators who qualify must post a 60-second video (using the hashtag #HOTD) that doesn’t violate TikTok’s policies.
The entertainment giant first experimented with the feature in February when it promoted “Dune: Part Two” on the platform. This resulted in over 260,000 fan-created posts in the two weeks leading up to the movie premiere, according to TikTok.
At launch, Spotlight will only be available to a select number of studios.
In the past, TikTok has provided marketing solutions for movie studio marketers, including Showtimes: movie trailer ads that display a “Get Showtimes” button to help users find nearby theater options and showtimes.
The company has also previously teamed up with ticketing companies Ticketmaster and AXS to let users purchase tickets for concerts and other live events directly through TikTok.

Today, during NBCUniversal’s annual technology conference, One24, the company revealed a slew of features coming to its streaming service Peacock ahead of the 2024 Paris Olympics in July.
The most notable feature to launch on Peacock is multiview, which allows subscribers to view up to four simultaneous matches at once. Next to picture-in-picture mode, many sports fans agree that multiview has been one of the greatest advancements to sports streaming tech in years, since it offers a more convenient way to follow multiple games simultaneously instead of constantly switching streams.
The company also announced a new interactive “Live Actions” button to let fans choose which events they want to follow, a new way to search for specific athletes, and other features designed to help subscribers navigate over 5,000 hours of live coverage for the upcoming Summer Olympics.
Some subscribers have complained about the way Peacock has broadcast the Olympics in the past, so it’s critical that the streamer provides an adequate viewing experience this year. For instance, during the 2022 Winter Olympic Games, Peacock made a questionable choice of revealing some of the winners in the Highlights rail. This will be the first time the service has done a full livestream of all Summer Olympic events, so we bet Peacock is feeling the pressure to get it right.
Peacock reported 31 million subscribers as of the fourth quarter of 2023.

Although YouTube TV and Apple both offer multiview features, Peacock told TechCrunch during a briefing on Tuesday that it’s the first stand-alone streaming service to offer web support for multiview. Google-owned YouTube TV rolled out a multiview feature last year that’s only available on smart TVs. In May 2023, Apple began offering multiview on the Apple TV 4K for select sports content, such as Major League Soccer and Major League Baseball streams.
Peacock also hopes to stand out among its competitors by offering two multiview options: “Discovery Multiview,” which gives fans a four-screen overview of the live events currently happening, and a more traditional multiview experience where viewers can choose which four matches they want to watch (this second option is only available for Olympic sports with multiple simultaneous streams, such as soccer, wrestling and track and field.) Both options are customizable, meaning viewers can move around the screens and seamlessly switch between audio feeds.
Since up to 40 Olympic events will be happening simultaneously, the unique offering helps viewers determine which four events are the most important. Plus, the feature will showcase tags and descriptions for each match to inform fans which ones have a first-time Olympian or defending champion or if there’s an elimination risk.
“With up to 40 events happening at the same time, we want to avoid users having decision paralysis.… [Peacock Discovery Multiview is] the perfect option for fans who want to lean back and let Peacock be their guide to the best of the Olympic Games,” Peacock SVP of Product John Jelley told TechCrunch.
Peacock’s multiview feature is available on the web, as well as on smart TVs, streaming devices, and tablets. However, the company explained to us that it isn’t rolling out multiview to mobile devices because the smaller screen size makes it difficult to navigate between events.
“It ultimately comes down to the screen size, and we’ve found that multiview on mobile doesn’t deliver the best viewing experience,” Jelley said. “For users who want to watch on the go, multiview is available on tablets, and of course across all other platforms.”
YouTube TV recently confirmed to 9to5Google that it’s launching support on iOS devices, but it’s likely the feature will be less advanced compared to the TV version.
Peacock will begin testing multiview during select events this spring.

In addition to multiview, the streaming service’s “Live Actions” will prompt fans to select a “Keep Watching” button if they want to continue viewing live coverage or switch to whip-around coverage. They can also add events to their “My Stuff” list to watch later.
A new “Search by Star Athlete” feature allows viewers to narrow down their search to their favorite athletes. Previously, they could only search by sport, event, team and country.
Peacock is also expanding its “Catch Up with Key Plays” feature to basketball, golf and soccer. The feature lets fans watch highlights of a game to quickly catch up without having to exit out of the main screen. It initially launched as a feature for Premier League games.
The company noted that multiview and Live Actions will extend to other live sporting events after the Olympics.
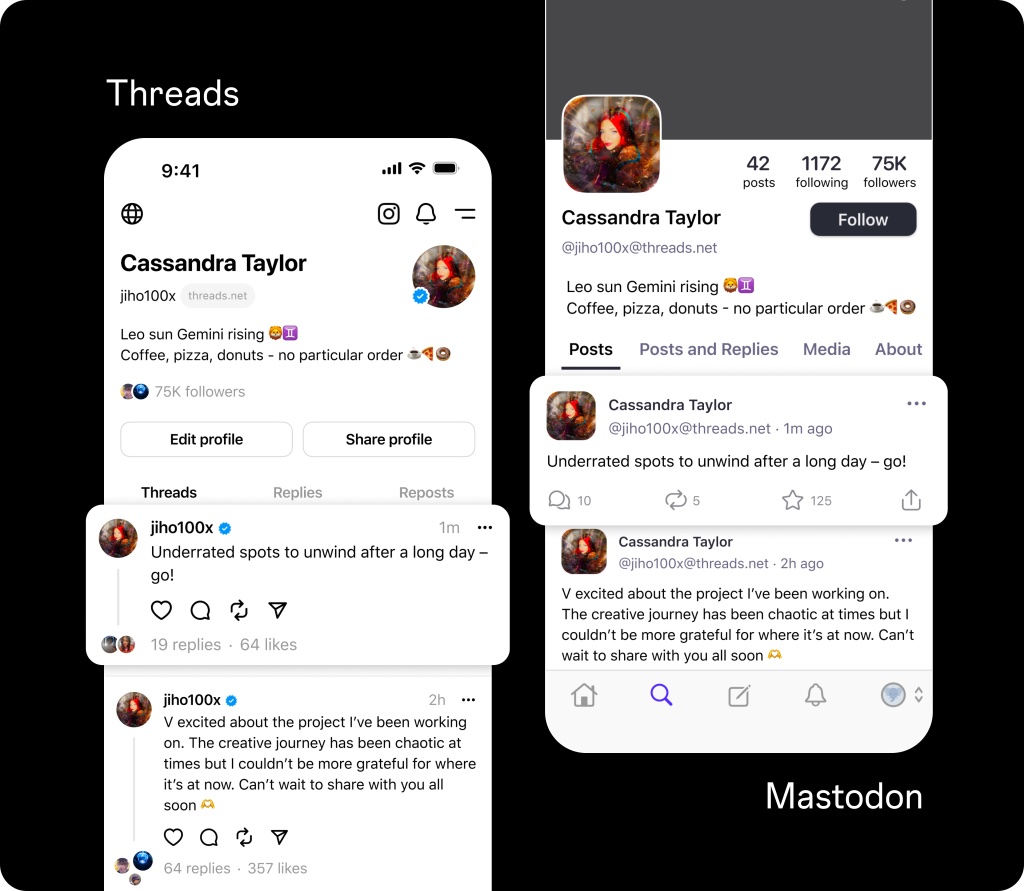
Threads has officially entered the fediverse. Meta announced on Thursday that its beta experience of sharing Threads accounts to the fediverse is now open to users ages 18 and up with public profiles. The integration is only available in three countries to start, including the U.S., Canada and Japan.
The company previously announced in December that it was testing the feature on Mastodon and other ActivityPub protocol-supported networks.
To opt into the integration, go to account settings and toggle on fediverse sharing. A pop-up will appear explaining what the fediverse is, which the company describes as a “social network of interconnected servers” where people can “follow other people on different servers to see and interact with their content — similar to how email allows people to communicate regardless of the services they choose.”
Once turned on, people on other servers (Mastodon, for example) can find your Threads profile and like, repost and share your posts with multiple audiences. This gives you the chance to connect with other people who may not be on Threads but use alternative social networking apps.

However, there are limitations. For instance, you won’t be able to see on Threads who replied or liked your posts from other servers. You also can’t share posts with polls. During the FediForum conference earlier this week, Meta’s Peter Cottle mentioned in his demo that the company was working on changing this.
Despite the drawbacks, it’s still notable that Meta is making Threads part of the decentralized social network system after only launching the app just eight months ago.
Meta starts testing Threads integration with ActivityPub

Keeping up with an industry as fast-moving as AI is a tall order. So until an AI can do it for you, here’s a handy roundup of recent stories in the world of machine learning, along with notable research and experiments we didn’t cover on their own.
This week in AI, I’d like to turn the spotlight on labeling and annotation startups — startups like Scale AI, which is reportedly in talks to raise new funds at a $13 billion valuation. Labeling and annotation platforms might not get the attention flashy new generative AI models like OpenAI’s Sora do. But they’re essential. Without them, modern AI models arguably wouldn’t exist.
The data on which many models train has to be labeled. Why? Labels, or tags, help the models understand and interpret data during the training process. For example, labels to train an image recognition model might take the form of markings around objects, “bounding boxes” or captions referring to each person, place or object depicted in an image.
The accuracy and quality of labels significantly impact the performance — and reliability — of the trained models. And annotation is a vast undertaking, requiring thousands to millions of labels for the larger and more sophisticated datasets in use.
So you’d think data annotators would be treated well, paid living wages and given the same benefits that the engineers building the models themselves enjoy. But often, the opposite is true — a product of the brutal working conditions that many annotation and labeling startups foster.
Companies with billions in the bank, like OpenAI, have relied on annotators in third-world countries paid only a few dollars per hour. Some of these annotators are exposed to highly disturbing content, like graphic imagery, yet aren’t given time off (as they’re usually contractors) or access to mental health resources.
Workers that made ChatGPT less harmful ask lawmakers to stem alleged exploitation by Big Tech
An excellent piece in NY Mag peels back the curtain on Scale AI in particular, which recruits annotators in countries as far-flung as Nairobi and Kenya. Some of the tasks required by Scale AI take labelers multiple eight-hour workdays — no breaks — and pay as little as $10. And these workers are beholden to the whims of the platform. Annotators sometimes go long stretches without receiving work, or they’re unceremoniously booted off Scale AI — as happened to contractors in Thailand, Vietnam, Poland and Pakistan recently.
Some annotation and labeling platforms claim to provide “fair-trade” work. They’ve made it a central part of their branding in fact. But as MIT Tech Review’s Kate Kaye notes, there are no regulations, only weak industry standards for what ethical labeling work means — and companies’ own definitions vary widely.
So, what to do? Barring a massive technological breakthrough, the need to annotate and label data for AI training isn’t going away. We can hope that the platforms self-regulate, but the more realistic solution seems to be policymaking. That itself is a tricky prospect — but it’s the best shot we have, I’d argue, at changing things for the better. Or at least starting to.
Here are some other AI stories of note from the past few days:
OpenAI builds a voice cloner: OpenAI is previewing a new AI-powered tool it developed, Voice Engine, that enables users to clone a voice from a 15-second recording of someone speaking. But the company is choosing not to release it widely (yet), citing risks of misuse and abuse.Amazon doubles down on Anthropic: Amazon has invested an additional $2.75 billion in the growing AI startup Anthropic, following through on the option it left open last September.Google.org launches an accelerator: Google.org, Google’s charitable wing, is launching a new $20 million, six-month program to help fund nonprofits developing tech that leverages generative AI.A new model architecture: AI startup AI21 Labs has released a generative AI model, Jamba, that employs a novel, new(ish) model architecture — state space models, or SSMs — to improve efficiency.Databricks launches DBRX: In other model news, Databricks this week released DBRX, a generative AI model akin to OpenAI’s GPT series and Google’s Gemini. The company claims it achieves state-of-the-art results on a number of popular AI benchmarks, including several measuring reasoning.Uber Eats and UK AI regulation: Natasha writes about how an Uber Eats courier’s fight against AI bias shows that justice under the U.K.’s AI regulations is hard won.EU election security guidance: The European Union published draft election security guidelines Tuesday aimed at the around two dozen platforms regulated under the Digital Services Act, including guidelines pertaining to preventing content recommendation algorithms from spreading generative AI–based disinformation (aka political deepfakes).Grok gets upgraded: X’s Grok chatbot will soon get an upgraded underlying model, Grok-1.5 — at the same time all Premium subscribers on X will gain access to Grok. (Grok was previously exclusive to X Premium+ customers.)Adobe expands Firefly: This week, Adobe unveiled Firefly Services, a set of more than 20 new generative and creative APIs, tools and services. It also launched Custom Models, which allows businesses to fine-tune Firefly models based on their assets — a part of Adobe’s new GenStudio suite.
How’s the weather? AI is increasingly able to tell you this. I noted a few efforts in hourly, weekly, and century-scale forecasting a few months ago, but like all things AI, the field is moving fast. The teams behind MetNet-3 and GraphCast have published a paper describing a new system called SEEDS ( Scalable Ensemble Envelope Diffusion Sampler).
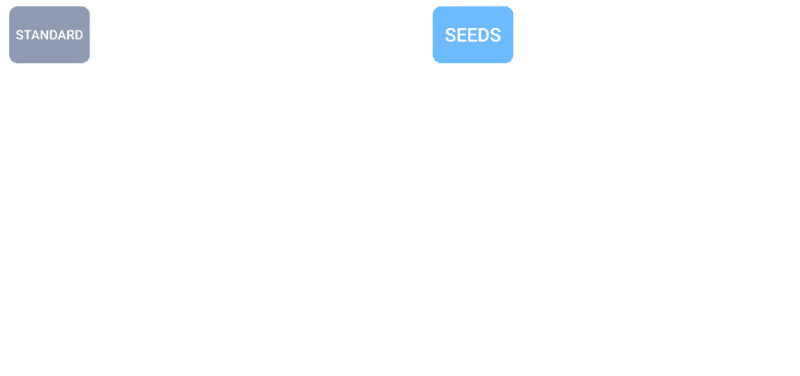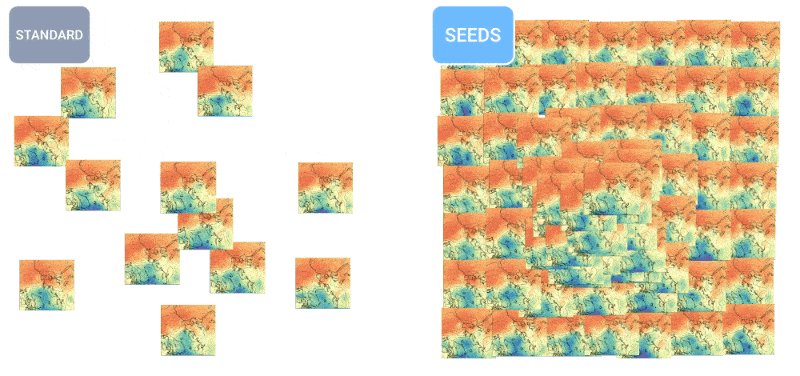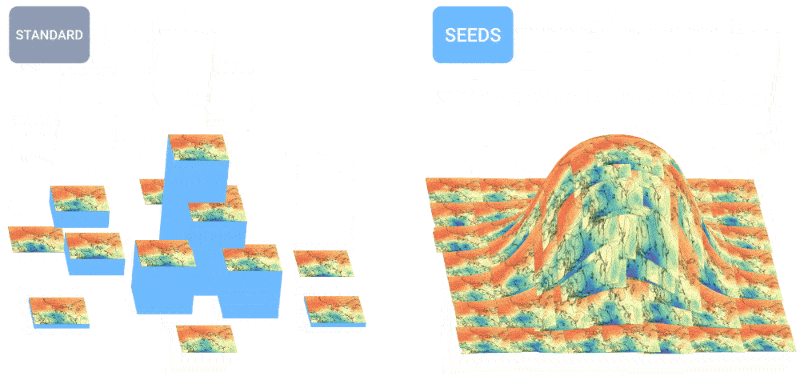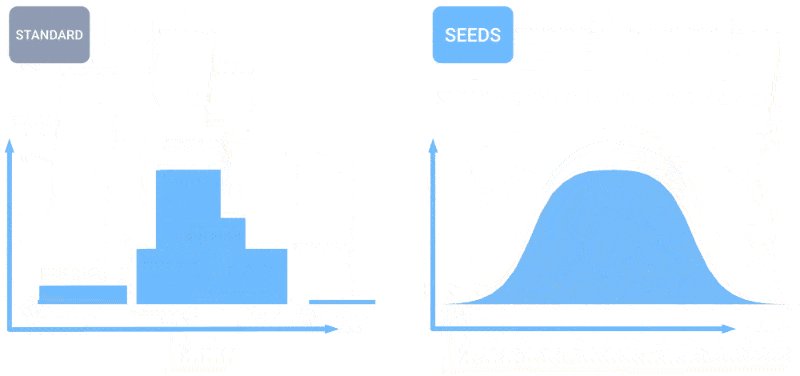
SEEDS uses diffusion to generate “ensembles” of plausible weather outcomes for an area based on the input (radar readings or orbital imagery perhaps) much faster than physics-based models. With bigger ensemble counts, they can cover more edge cases (like an event that only occurs in 1 out of 100 possible scenarios) and can be more confident about more likely situations.
Fujitsu is also hoping to better understand the natural world by applying AI image handling techniques to underwater imagery and lidar data collected by underwater autonomous vehicles. Improving the quality of the imagery will let other, less sophisticated processes (like 3D conversion) work better on the target data.
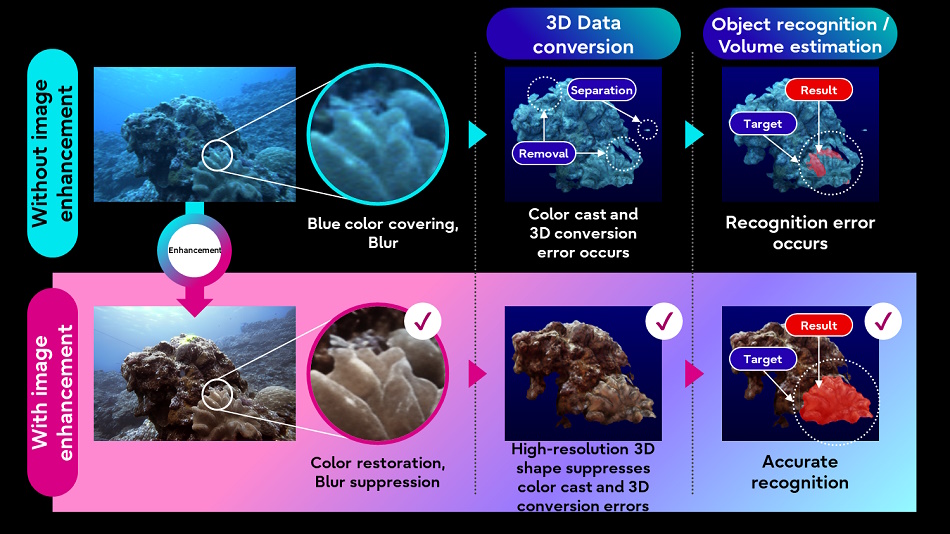
The idea is to build a “digital twin” of waters that can help simulate and predict new developments. We’re a long way off from that, but you gotta start somewhere.
Over among the large language models (LLMs), researchers have found that they mimic intelligence by an even simpler-than-expected method: linear functions. Frankly, the math is beyond me (vector stuff in many dimensions) but this writeup at MIT makes it pretty clear that the recall mechanism of these models is pretty … basic.
Even though these models are really complicated, nonlinear functions that are trained on lots of data and are very hard to understand, there are sometimes really simple mechanisms working inside them. “This is one instance of that,” said co-lead author Evan Hernandez. If you’re more technically minded, check out the researchers’ paper here.
One way these models can fail is not understanding context or feedback. Even a really capable LLM might not “get it” if you tell it your name is pronounced a certain way, since they don’t actually know or understand anything. In cases where that might be important, like human-robot interactions, it could put people off if the robot acts that way.
Disney Research has been looking into automated character interactions for a long time, and this name pronunciation and reuse paper just showed up a little while back. It seems obvious, but extracting the phonemes when someone introduces themselves and encoding that rather than just the written name is a smart approach.

Lastly, as AI and search overlap more and more, it’s worth reassessing how these tools are used and whether there are any new risks presented by this unholy union. Safiya Umoja Noble has been an important voice in AI and search ethics for years, and her opinion is always enlightening. She did a nice interview with the UCLA news team about how her work has evolved and why we need to stay frosty when it comes to bias and bad habits in search.
Why it’s impossible to review AIs, and why TechCrunch is doing it anyway

In the generative AI boom, data is the new oil. So why shouldn’t you be able to sell your own?
From Big Tech firms to startups, AI makers are licensing e-books, images, videos, audio and more from data brokers, all in the pursuit of training up more capable (and more legally defensible) AI-powered products. Shutterstock has deals with Meta, Google, Amazon and Apple to supply millions of images for model training, while OpenAI has signed agreements with several news organizations to train its models on news archives.
In many cases, the individual creators and owners of that data haven’t seen a dime of the cash changing hands. A startup called Vana wants to change that.
Anna Kazlauskas and Art Abal, who met in a class at the MIT Media Lab focused on building tech for emerging markets, co-founded Vana in 2021. Prior to Vana, Kazlauskas studied computer science and economics at MIT, eventually leaving to launch a fintech automation startup, Iambiq, out of Y Combinator. Abal, a corporate lawyer by training and education, was an associate at The Cadmus Group, a Boston-based consulting firm, before heading up impact sourcing at data annotation company Appen.
With Vana, Kazlauskas and Abal set out to build a platform that lets users “pool” their data — including chats, speech recordings and photos — into datasets that can then be used for generative AI model training. They also want to create more personalized experiences — for instance, daily motivational voicemail based on your wellness goals, or an art-generating app that understands your style preferences — by fine-tuning public models on that data.
“Vana’s infrastructure in effect creates a user-owned data treasury,” Kazlauskas told TechCrunch. “It does this by allowing users to aggregate their personal data in a non-custodial way … Vana allows users to own AI models and use their data across AI applications.”
Here’s how Vana pitches its platform and API to developers:
The Vana API connects a user’s cross-platform personal data … to allow you to personalize your application. Your app gains instant access to a user’s personalized AI model or underlying data, simplifying onboarding and eliminating compute cost concerns. … We think users should be able to bring their personal data from walled gardens, like Instagram, Facebook and Google, to your application, so you can create amazing personalized experiences from the very first time a user interacts with your consumer AI application.
Creating an account with Vana is fairly simple. After confirming your email, you can attach data to a digital avatar (e.g., selfies, a description of yourself and voice recordings) and explore apps built using Vana’s platform and datasets. The app selection ranges from ChatGPT-style chatbots and interactive storybooks to a Hinge profile generator.

Now, why, you might ask — in this age of increased data privacy awareness and ransomware attacks — would someone ever volunteer their personal info to an anonymous startup, much less a venture-backed one? (Vana has raised $20 million to date from Paradigm, Polychain Capital and other backers.) Can any profit-driven company really be trusted not to abuse or mishandle any monetizable data it gets its hands on?

In response to that question, Kazlauskas stressed that the whole point of Vana is for users to “reclaim control over their data,” noting that Vana users have the option to self-host their data rather than store it on Vana’s servers and control how their data’s shared with apps and developers. She also argued that, because Vana makes money by charging users a monthly subscription (starting at $3.99) and levying a “data transaction” fee on devs (e.g., for transferring datasets for AI model training), the company is disincentivized to exploit users and the troves of personal data they bring with them.
“We want to create models owned and governed users who all contribute their data,” Kazlauskas said, “and allow users to bring their data and models with them to any application.”
Now, while Vana isn’t selling users’ data to companies for generative AI model training (or so it claims), it wants to allow users to do this themselves if they choose — starting with their Reddit posts.
This month, Vana launched what it’s calling the Reddit Data DAO (Digital Autonomous Organization), a program that pools multiple users’ Reddit data (including their karma and post history) and lets them decide together how that combined data is used. After joining with a Reddit account, submitting a request to Reddit for their data and uploading that data to the DAO, users gain the right to vote alongside other members of the DAO on decisions like licensing the combined data to generative AI companies for a shared profit.
We have crunched the numbers and r/datadao is now largest data DAO in history: Phase 1 welcomed 141,000 reddit users with 21,000 full data uploads.
— r/datadao (@rdatadao) April 11, 2024
It’s an answer of sorts to Reddit’s recent moves to commercialize data on its platform.
Reddit previously didn’t gate access to posts and communities for generative AI training purposes. But it reversed course late last year, ahead of its IPO. Since the policy change, Reddit has raked in over $203 million in licensing fees from companies, including Google.
“The broad idea [with the DAO is] to free user data from the major platforms that seek to hoard and monetize it,” Kazlauskas said. “This is a first and is part of our push to help people pool their data into user-owned datasets for training AI models.”
Unsurprisingly, Reddit — which isn’t working with Vana in any official capacity — isn’t pleased about the DAO.
Reddit banned Vana’s subreddit dedicated to discussion about the DAO. And a Reddit spokesperson accused Vana of “exploiting” its data export system, which is designed to comply with data privacy regulations like the GDPR and California Consumer Privacy Act.
“Our data arrangements allow us to put guardrails on such entities, even on public information,” the spokesperson told TechCrunch. “Reddit does not share non-public, personal data with commercial enterprises, and when Redditors request an export of their data from us, they receive non-public personal data back from us in accordance with applicable laws. Direct partnerships between Reddit and vetted organizations, with clear terms and accountability, matters, and these partnerships and agreements prevent misuse and abuse of people’s data.”
But does Reddit have any real reason to be concerned?
Kazlauskas envisions the DAO growing to the point where it impacts the amount Reddit can charge customers for its data. That’s a long ways off, assuming it ever happens; the DAO has just over 141,000 members, a tiny fraction of Reddit’s 73-million-strong user base. And some of those members could be bots or duplicate accounts.
Then there’s the matter of how to fairly distribute payments that the DAO might receive from data buyers.
Currently, the DAO awards “tokens” — cryptocurrency — to users corresponding to their Reddit karma. But karma might not be the best measure of quality contributions to the dataset — particularly in smaller Reddit communities with fewer opportunities to earn it.
Kazlauskas floats the idea that members of the DAO could choose to share their cross-platform and demographic data, making the DAO potentially more valuable and incentivizing sign-ups. But that would also require users to place even more trust in Vana to treat their sensitive data responsibly.
Personally, I don’t see Vana’s DAO reaching critical mass. The roadblocks standing in the way are far too many. I do think, however, that it won’t be the last grassroots attempt to assert control over the data increasingly being used to train generative AI models.
Startups like Spawning are working on ways to allow creators to impose rules guiding how their data is used for training while vendors like Getty Images, Shutterstock and Adobe continue to experiment with compensation schemes. But no one’s cracked the code yet. Can it even be cracked? Given the cutthroat nature of the generative AI industry, it’s certainly a tall order. But perhaps someone will find a way — or policymakers will force one.

Social networks Bluesky and Mastodon may soon be accessible from within a single app — at least, that’s what Bluesky hopes. The new decentralized social network, originally incubated inside Jack Dorsey-run Twitter, is backing a project that would connect — or “bridge” — Mastodon requests into Bluesky requests so that consumer apps, like Ivory, would be compatible with Bluesky, too.
The project, dubbed SkyBridge, was among the recipients of a small distribution of $4,800 in grant funding from Bluesky, distributed across projects. SkyBridge was the second-largest recipient in this current cohort, with $800 of the total.
Bluesky had announced last month that it would use some portion of its funds to fuel efforts in the developer ecosystem via the AT Protocol Grant program. From a financial standpoint, the program is fairly insignificant, as it’s only doling out $10,000 in grants, with $4,800 already distributed. That’s not enough to found a new company in this space, but it represents a way to encourage developers who may have wanted to dig into the new AT Protocol anyway. It also serves as an early signal of the kind of development work Bluesky supports — something that could help drive adoption among developers who have been previously (and repeatedly) burned by Twitter and its changing priorities.
Other program recipients are doing valuable work as well.
For example, Blacksky Algorithms is building a suite of services to provide custom moderation services for Bluesky’s Black users. Others are building Bluesky consumer apps, developer tools, analytics resources and more.
But SkyBridge is particularly interesting because it could potentially open the small startup to a wider audience.
Twitter’s restrictive API may leave researchers out in the cold
Unlike Mastodon and other decentralized apps powered by the older ActivityPub protocol, Bluesky is developing a new, decentralized social networking protocol. Unfortunately, for end users who have begun exploring the open source social networks broadly known as the “fediverse,” Bluesky’s decision to build on a different protocol means users have to switch apps to access Bluesky’s network. They can’t use their preferred Mastodon app to browse Bluesky content, that is.
If successful, SkyBridge could change that, as it would be able to translate Mastodon API calls to Bluesky API calls. The bridge is currently being tested on Ivory on iOS and Mac; it’s the Mastodon app from the company that previously developed a popular third-party Twitter app called Tweetbot. Notes SkyBridge’s developer @videah.net on Bluesky, the project is currently undergoing a significant rewrite from Dart to Rust, which is why its GitHub repo hasn’t seen much activity lately.
Still, he thinks the work is promising.
“It’s already proving to be much more stable, hoping to show it off soon,” videah posted on Bluesky when sharing the news of the grant.
Today, Bluesky has nearly 5.6 million users, while the wider ActivityPub-backed fediverse has over 10 million users. Instagram Threads (which is integrating with ActivityPub) now has more than 150 million monthly active users, Meta announced this week during earnings.
The move to bridge Bluesky and Mastodon has been the subject of some debate as of late. People have disagreed on how bridging should be done, or whether a bridge should be built at all. Another software developer, Ryan Barrett, was the recipient of some backlash on GitHub when building another bridge called Bridgy Fed, which would be opt-out by default — meaning Mastodon posts would show up on Bluesky even if the post’s author hadn’t opted into this. He readjusted his plans to build a discoverable opt-in instead, which would allow users to request to follow accounts on the different networks.
With its backing of SkyBridge, Bluesky is signaling a desire to blur the lines between Mastodon and Bluesky.
Eventually, people may not need to think about what protocol an app runs on, just like no one thinks about their email client using SMTP, POP3 or IMAP. And in an ideal outcome, people could connect to friends on any social network, regardless of its underpinning, and see their friends’ replies in return, too.
Bluesky and Mastodon users are having a fight that could shape the next generation of social media

Meta is updating its Ray-Ban smart glasses with new hands-free functionality, the company announced on Wednesday. Most notably, users can now share an image from their smart glasses directly to their Instagram Story without needing to take out their phone.
After you take a photo with the smart glasses, you can say, “Hey Meta, share my last photo to Instagram.” Or you can say, “Hey Meta, post a photo to Instagram” to take a new photo in the moment.
The launch of the new feature is reminiscent of the Snap Spectacles, which debuted in 2016 and allowed users to capture photos and videos with their smart glasses to share them directly to their Snapchat Stories.
Meta’s Ray-Ban smart glasses are also getting hands-free integrations with Amazon Music and meditation app Calm.
Users can now stream music from Amazon Music without having to take out their phone by saying “Hey Meta, play Amazon Music.” You can also control your audio playback with touch or voice controls while your phone stays in your pocket.
To access the new hands-free Calm integration, users can say “Hey Meta, play the Daily Calm” to have mindfulness exercises and self-care content accessible directly through their smart glasses.
In addition, Meta is expanding the number of styles available in 15 countries, including the U.S., Canada, Australia and parts Europe. The expansion includes the style Skyler in Shiny Chalky Gray with Gradient Cinnamon Pink Lenses; Skyler in Shiny Black with Transitions Cerulean Blue Lenses; and Headliner Low Bridge Fit in Shiny Black with Polar G15 Lenses. The glasses are available on both Meta’s and Ray-Ban’s websites.
The launch of the new features comes a month after the smart glasses got an AI upgrade. Meta rolled out multimodal AI to the smart glasses to enable users to ask questions about what they see. For instance, if you’re seeing a menu in French, the smart glasses could use their built-in camera and Meta AI to translate the text for you.
The idea behind the launch is to allow the smart glasses to act as a personal AI assistant outside of your smartphone, in a way that’s similar to Humane’s Ai pin.